Hey there! I'm Shivani, a grad student at NYU, diving deep into the world of Computer Engineering. My passion for Data Science has led me through exciting courses like Probability, Programming for Data Science, Machine Learning, Deep Learning, and Natural Language Understanding. These experiences have given me a solid foundation in the math and algorithms behind Data Science.
Currently, I'm a Graduate Research Assistant, working with Professor Yiding Hao on making Large Language Models more interpretable using innovative techniques like Boundless Distributed Alignment Search. This past summer, I interned at Meted LLC, an edtech startup, where I helped build a personal tutor API using PyTorch, GPT-3, LangChain, Flask, and VectorDB. Before my grad studies, I spent 3.5 years as a Senior Analyst at Citibank, where I optimized real-time trade processing across different assets using Spark, Kafka, and Gemfire. I also collaborated with the Data and Regulatory team to develop critical report-generation tools. Working in fintech exposed me to handling critical, sensitive data and implementing efficient solutions within constrained environments.
Performed Exploratory Data Analysis for hypothesis testing and achieved an accuracy of ~95% using CatBoost Regression based on 50.68 GB anonymized and normalized data in Parquet provided by AMEX. Implemented a causal inference model to assess credit card applicants' credit risk, used a custom ML wrapper to encapsulate the algorithm, and passed it to the MLOps pipeline to facilitate deployment and monitoring. Check it out!
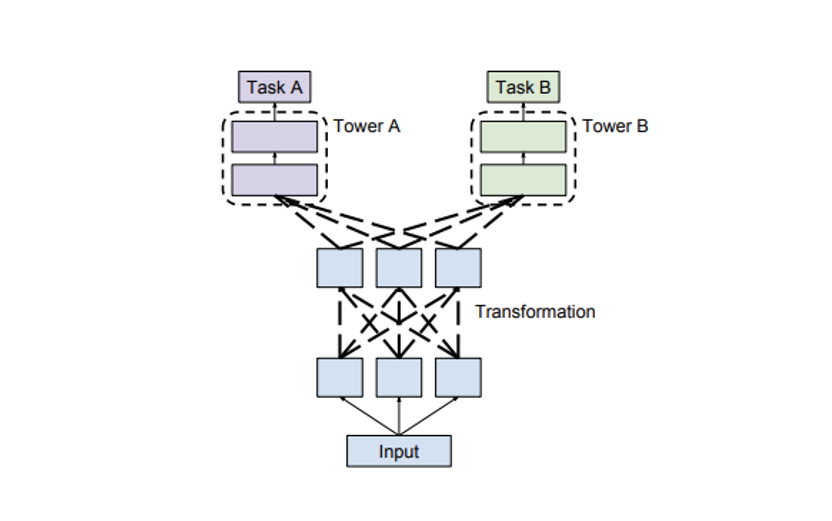
Engineered and deployed a novel multi-task learning approach that uses a pre-trained Language Model to simultaneously fine-tune Named Entity Recognition and domain-specific Question-Answering tasks in mini-batches.
Achieved 0.925 F1-score on SQUAD dataset and 0.828 F1-score on NewsQA demonstrating increased performance compared to the single-task BERT model
Check it out!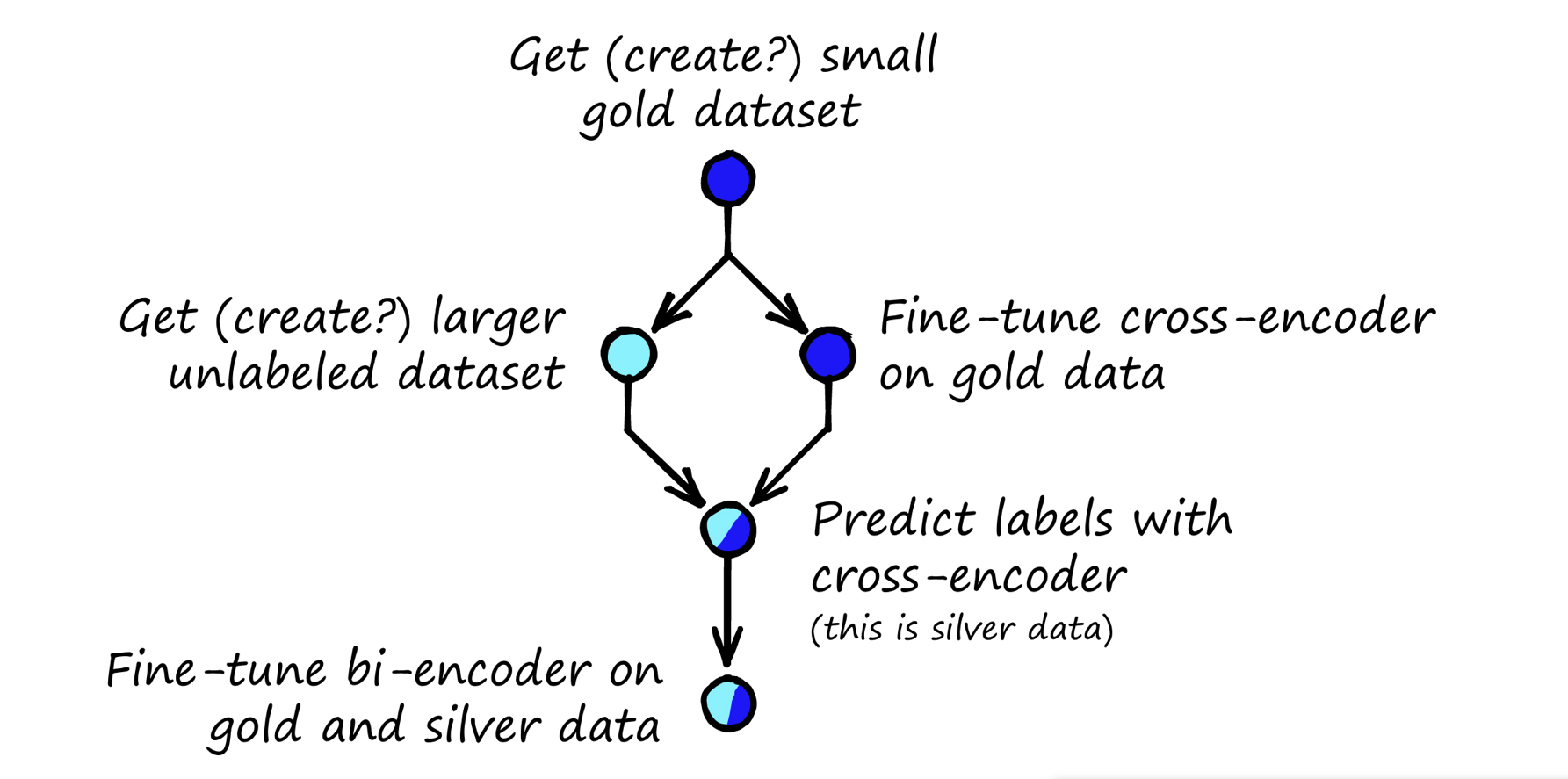
Performed a successful assessment of GPT models in tandem with bootstrapping Neural Relation and Explanation Classifiers to infer rules from labeled data in low-resourced settings.
Improved the accuracy for predicting correct labels for unlabelled data by 15% compared to the SOTA model for the TACRED relation extraction dataset.
Check it out!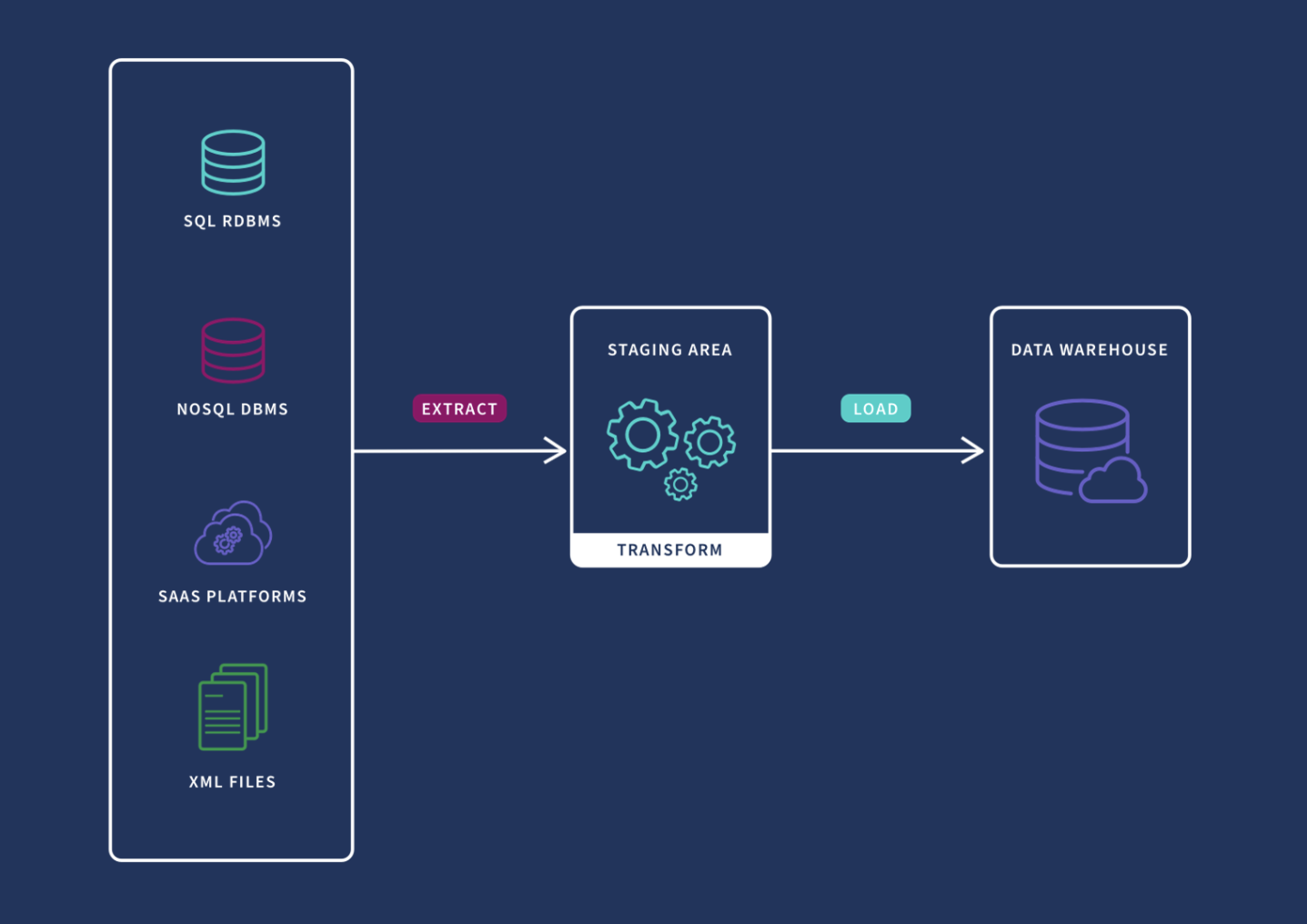
Implemented a Python-based pipeline to efficiently process and integrate financial data from diverse sources, including CSV files and RESTful APIs, obtained from the US Securities and Exchange Commission (SEC).
Utilized SQL to perform data extraction and transformation, ensuring data quality and consistency, and created an interactive dashboard using Tableau for data visualization.
Check it out!